



Fermi技术细节抢先预览
核心才是关键——第三代Streaming Multiprocessor
虽然在CUDA的概念里,CUDA Core或者Streaming Processor内核(简称"SP")指的就是一个处理核心。但其实SP只是一个功能单元,真正比较接近于我们常说的内核则是SP的上一级单位——Streaming Multiprocessor(简称"SM")。因为目前只有在SM这一级才具备Program Counter(程序计数器)、调度资源以及分离的寄存器堆块,即才能进行CUDA计算。在AMD统一着色器架构的GPU中,类似SM等级的部件是SIMD Core,例如RV870拥有20个SIMD Core。
双精度计算的好处
双精度计算能力直接决定了线性代数、数值模拟、量子化学等高性能计算(HPC)应用程序的执行效率,Fermi为此进行了专门的设计,提供了前所未有的双精度性能——一个SM每周期能执行高达16个双精度的FMA指令。
按照NVIDIA透露的初步资料,第一款Fermi架构的GPU将会有16组SM,每一组SM包含了32个SP,每个SP都有全流水线化的整数算术逻辑单元(ALU)和浮点单元(FPU)。ALU支持64bit和扩展指令,支持算术、shift(位移)、Boolean(布尔)、comparision(比较)以及move(数据传输或者赋值)。

第一款Fermi GPU的体系结构图
虽然Fermi的SM数量从GT200的30个下降为16个,但SP总数却达到了512个(GT200为30×8=240个),实际的单周期理论性能则提升了近1倍甚至更多(例如双精度浮点运算)。
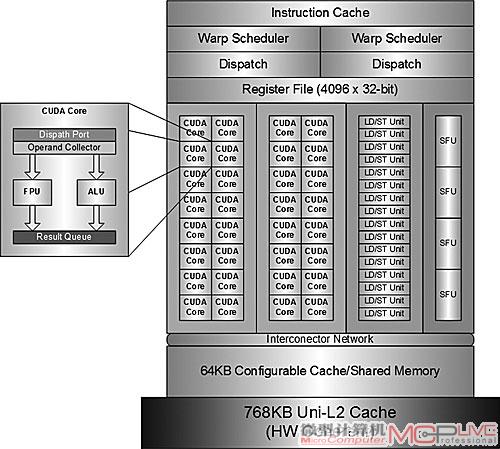
一组SM包含了32个SP
另外,一个SP每个周期可以实现一个Thread的一条浮点指令或者整数指令;该GPU上有六块64bit的内存分区,能提供384-bit的内存数据总线,可以支持多达6GB甚至更多的GDDR5内存。
好事成双——Dual Warp Scheduler(双Warp调度器)
按照NVIDIA的说法,Fermi的SM拥有两个Warp Scheduler(简称"DWS")和两个指令分发单元,允许两个Warp同时发射和执行。DWS会挑选出两个Warp并对每个Warp各发射一条指令到不同的执行块。NVIDIA并没有具体透露这里的“执行块”是什么,笔者估计可能是指SM中的SP被划分成若干个组或者是不同的指令执行端口。在CUDA的并行编程模型下,大多数的指令都能实现双发射,例如:两条整数指令、两条浮点指令或者整数+浮点的组合。
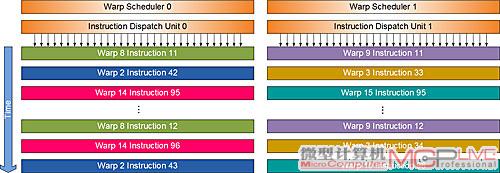
一个SM具备两个DWS
什么是Warp?
Warp是SM的处理宽度,或者说是SM的SIMD宽度。每次指令发射,都是以一个Warp为一个单位,G80和GT200发射一次指令执行一个Warp,一个Warp需要4个周期。
数据交换的法宝——灵活多变的Shared memory和L1/L2 Cach
每个SM里面拥有一个容量很小的内存空间,即Shared Memory,可以用于数据交换,程序员可以方便自由使用。有了Shared memory后,同一个Thread block内的线程可以共享数据,极大地提升了NVIDIA GPU在进行GPU Computing应用时的效率。
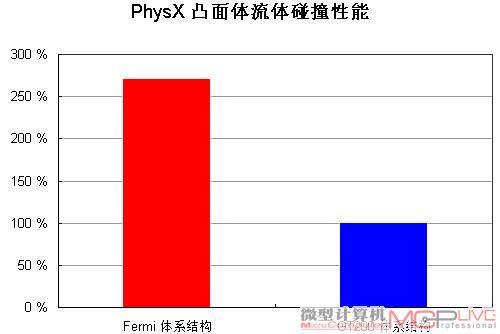
Fermi的Cache设计对物理算法例如流体模拟来说有莫大的好处,
在PhysX凸面流体碰撞放运算方面,Fermi的性能大幅领先GT200。
虽然Shared memory对许多计算都有帮助,但它并不适用于所有的问题。佳化的内存层次架构方案就是同时提供shared memory和cache,Fermi就采用了这样的设计。在G80和GT200中,每个SM都有16KB的Shared memory。而在Fermi中,每个SM拥有64KB的Shared memory,能配置为48KB Sharedmemory+16KB L1 cache或者16KB Shared memory+48KB L1 cache的模式(G80和GT200不具备L1/L2 cache)。程序员可以自己编写一段小的程序,把Shared memory当成Cache来使用,由软件负责实现数据的读写和一致性管理。而对那些不具备上述程序的应用程序来说,也可以直接自动从L1 Cache中受益,显著缩减运行CUDA程序的时间。
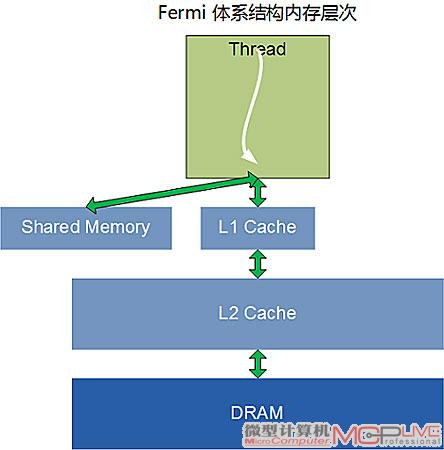
L1/L2 Cach是Fermi的内存层次系统中的创新设计
过去,GPU的寄存器如果发生溢出的话,会大幅度地增加存取时延。有了L1 cache以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落。
另外,Fermi提供了768kB 的一体化L2 cache,L2 cache为所有的Load/Store以及纹理请求提供高速缓存。对所有的SM来说,L2 cache上的数据都是连贯一致的,从L2 cache上读取到的数据就是新的数据。有了L2 cache后,就能实现GPU高效横跨数据共享。对于那些无法预知数据地址的算法,例如物理解算器、光线追踪以及稀疏矩阵乘法都可以从Fermi的内存层次设计中显著获益。而对于需要多个SM读取相同数据的滤镜以及卷积核(convolution kernel)等算法同样能因为这个设计而获益。
用户评论
-
-
-
事实上NV现在是不是技术的成功者也值得探讨。N和A的架构孰优孰劣只能透过实际检验来衡量,事实上如果所有的测试或者游戏都关闭了优化的元素之后,两家厂商的芯片性能其实一直是在伯仲之间。 Fermi的架构看图的确很吸引人,但是NV忘了一样东西,那就是想象可以无限大,但是后却都只能立足于一片小硅片之上。随着GPU功能的复杂化,制程的更新已经明显跟不上,Fermi迟迟不能生产就是好的例子。NV继续坚持大芯片的道路现在看来无疑是错误的。 事实上NV的确很厉害,它拥有一大堆自有标准,例如PhysX和CUDA。它的确一呼百应,一大堆THE WAY游戏就是证明。但是,今天的NV和当初的3dfx何其相似,抱着自有的标准,做着黄粱美梦。事实上,任何的标准都可以有替代品。当年DirectX替代了GLIDE,今天同样Direct Computing和OpenCL可以替代CUDA和PhysX。希望NV还是要踏踏实实做好芯片的研发,不要以为自有标准是万能的。所谓的合作伙伴都是商人,商人是唯利是图的,当年他们可以抛弃3dfx,今天就可以抛弃NV。
-
-

