



Fermi技术细节抢先预览
底层的革新——内存子系统特性的变化
服务于HPC市场——第一颗支持ECC技术的GPU
对一般的游戏来说,色彩数据值的一个位元或者多个位元出现错误并不会对游戏产生多大的影响,但是在诸如气象模拟、石油勘探和地震监测等HPC的应用中却可能会造成重大危害。辐射可能会导致内存中的某些数据受到影响,从而产生一个软错误。
ECC技术可以在这些单个位元的软错误对系统产生影响之前就侦测到这些错误并予以修正,因此ECC已经是大规模集群设备必不可少的技术。GT200虽然可以支持双精度浮点运算,但是由于缺乏ECC的支持,实际上并没有在HPC市场中有重大的建树。而Fermi的寄存器堆、shared memory、L1 cache、L2 cache以及DRAM内存都受ECC技术保护,使得Fermi有望成为HPC应用方面性能强大的GPU。
高优先等级——快速原子内存操作
原子内存操作对于并行编程是非常重要的,它可以让并发线程正确地在共享数据结构上执行“读取→修改→写入”操作。像add、min、max以及compare-and-swap这类原子内存操作的优势在于它们在执行读取、修改以及写入操作时不会被其它线程中断。原子内存操作广泛应用于排序(sorting)、归约操作(reduction operation)应用中,甚至可以在非锁定(锁定会导致线程执行串行化)情况下以并行方式建立数据结构。
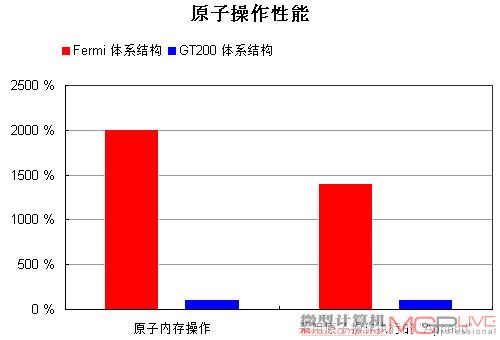
Fermi的原子内存操作能力大大领先GT200
得益于更多的原子操作单元以及L2 cache,Fermi的原子内存操作性能相对以往的架构来说得到了巨大的提升。对同一地址的原子内存操作,Fermi的运算速度是GT200的20倍,而对相邻内存区域的操作则达到7.5倍。
什么是原子内存操作?
原子内存操作是一个不能被其它线程干扰的操作。例如要把一个数据写到一个地址a里,在多线程中,可能有很多个线程都想对地址a进行操作(读、写、修改等),原子内存操作就是必须待这个原子内存操作完成后,其它线程才能对这个地址进行操作。
用户评论
-
-
-
事实上NV现在是不是技术的成功者也值得探讨。N和A的架构孰优孰劣只能透过实际检验来衡量,事实上如果所有的测试或者游戏都关闭了优化的元素之后,两家厂商的芯片性能其实一直是在伯仲之间。 Fermi的架构看图的确很吸引人,但是NV忘了一样东西,那就是想象可以无限大,但是后却都只能立足于一片小硅片之上。随着GPU功能的复杂化,制程的更新已经明显跟不上,Fermi迟迟不能生产就是好的例子。NV继续坚持大芯片的道路现在看来无疑是错误的。 事实上NV的确很厉害,它拥有一大堆自有标准,例如PhysX和CUDA。它的确一呼百应,一大堆THE WAY游戏就是证明。但是,今天的NV和当初的3dfx何其相似,抱着自有的标准,做着黄粱美梦。事实上,任何的标准都可以有替代品。当年DirectX替代了GLIDE,今天同样Direct Computing和OpenCL可以替代CUDA和PhysX。希望NV还是要踏踏实实做好芯片的研发,不要以为自有标准是万能的。所谓的合作伙伴都是商人,商人是唯利是图的,当年他们可以抛弃3dfx,今天就可以抛弃NV。
-
-

